cpanm Astro::FITS::CFITSIO
require("FITSio")
pyBLoCXS in Sherpa
We will first demonstrate standard analysis. We will run a Sherpa fit, and then a Bayesian MCMC fit, and compare the results.
Unzip and untar the data:
unix> ls obs866/
acis.asphist
acis.pi
acis.rmf
acis_bg.pi
unix> sherpa
sherpa> load_data("obs866/acis.pi")
read RMF file obs866/acis.rmf
read background file obs866/acis_bg.pi
#(this is the step I forgot to do during the live demo at IACHEC)
sherpa> set_model(xsphabs.abs1*xspowerlaw.p1) #an absorbed power-law
sherpa> set_stat('cstat') #pyBLoCXS only works with cstat
sherpa> set_method('neldermead')
sherpa> fit()
sherpa> covar()
covariance 1-sigma (68.2689%) bounds: Param Best-Fit Lower Bound Upper Bound ----- -------- ----------- ----------- abs1.nH 0.103681 -0.00569035 0.00569035 p1.PhoIndex 1.24369 -0.0217466 0.0217466 p1.norm 0.000581215 -1.26871e-05 1.26871e-05
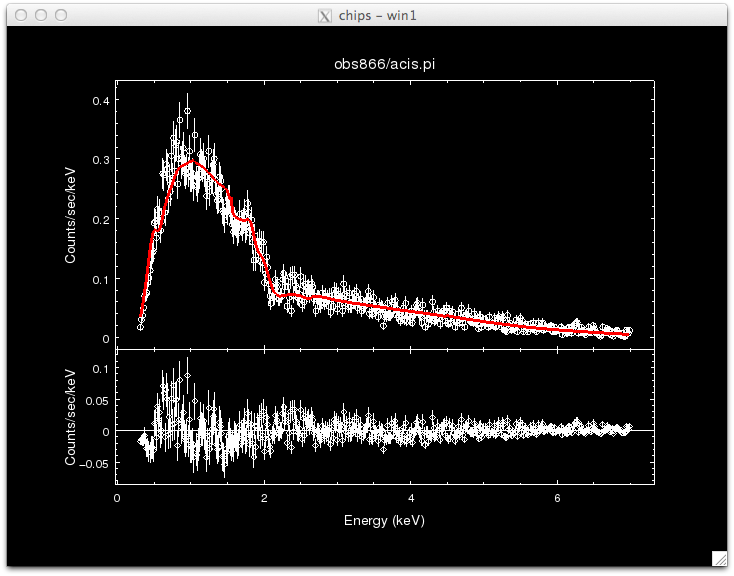
confidence 1-sigma (68.2689%) bounds: Param Best-Fit Lower Bound Upper Bound ----- -------- ----------- ----------- abs1.nH 0.103681 -0.00569035 0.00569035 p1.PhoIndex 1.24369 -0.0217466 0.0217466 p1.norm 0.000581215 -1.2588e-05 1.28854e-05
Now, do a pyBLoCXS run. pyBLoCXS requires that a standard fit() and a covar() be run beforehand, so we can continue from where we stopped above. To run pyBLoCXS, we have to choose a sampler. There are four recognized currently in Sherpa, of which three are implemented.
['metropolismh', 'fullbayes', 'mh', 'pragbayes']
Then, call pyBLoCXS:
Notice that the call to pyBLoCXS is made through the function get_draws(), and it returns 3 outputs, the statistic value at each iteration, whether the draw was accepted or not, and the parameter values in the MCMC chain for each iteration, in that order.
We can see see what the best-fit values are by finding the parameter values that correspond to the minimum statistic.
array([ 1.03680945e-01, 1.24369149e+00, 5.81215353e-04])
[0.0054630064588717586, 0.021625075347852889, 1.2220452692220281e-05]
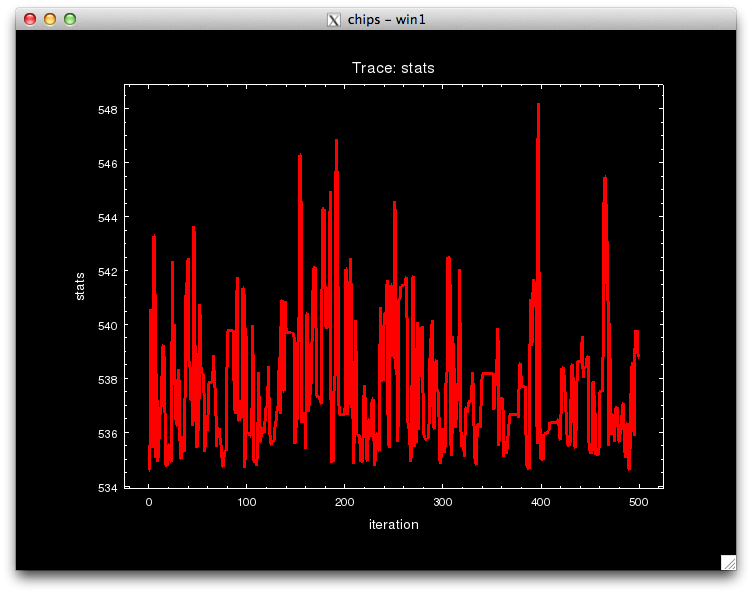
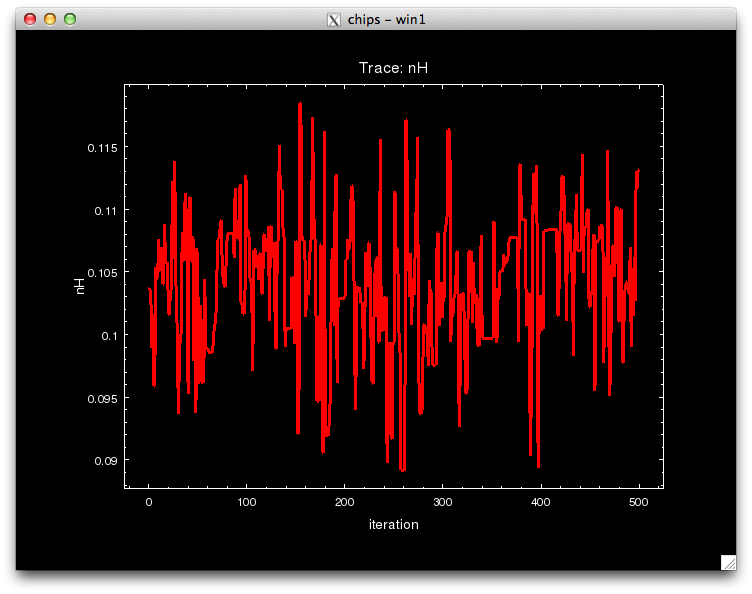
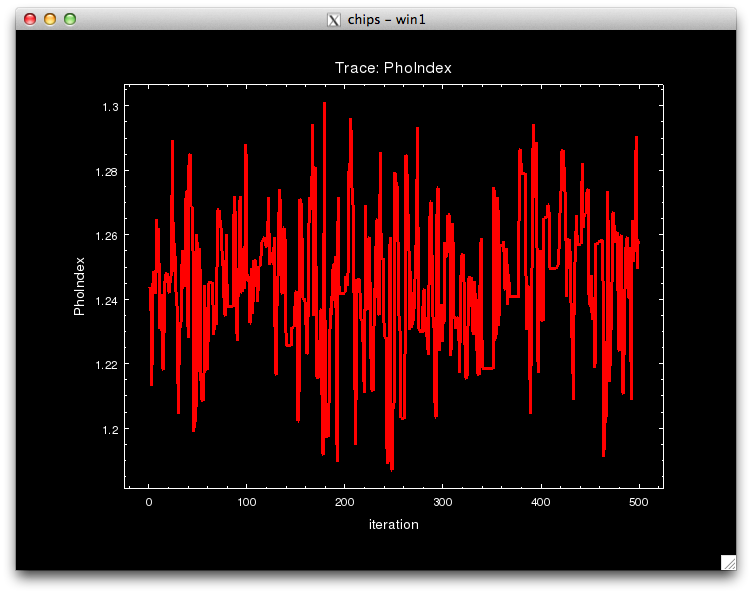
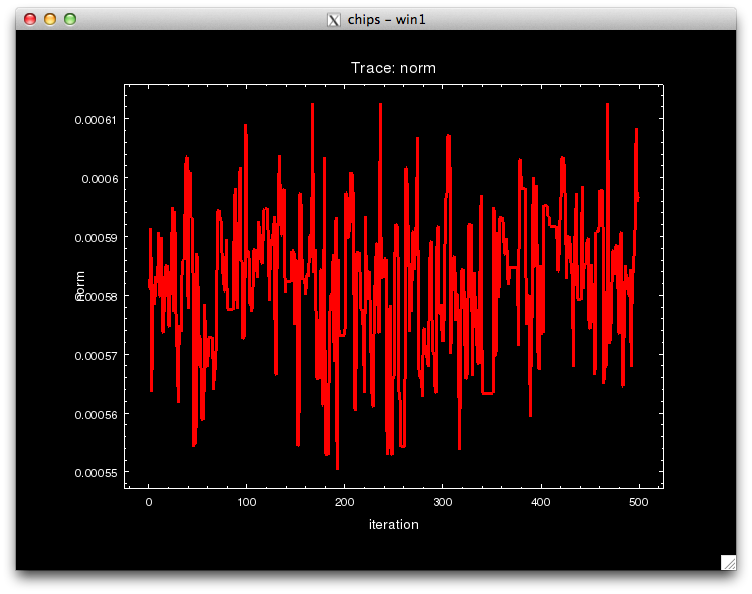
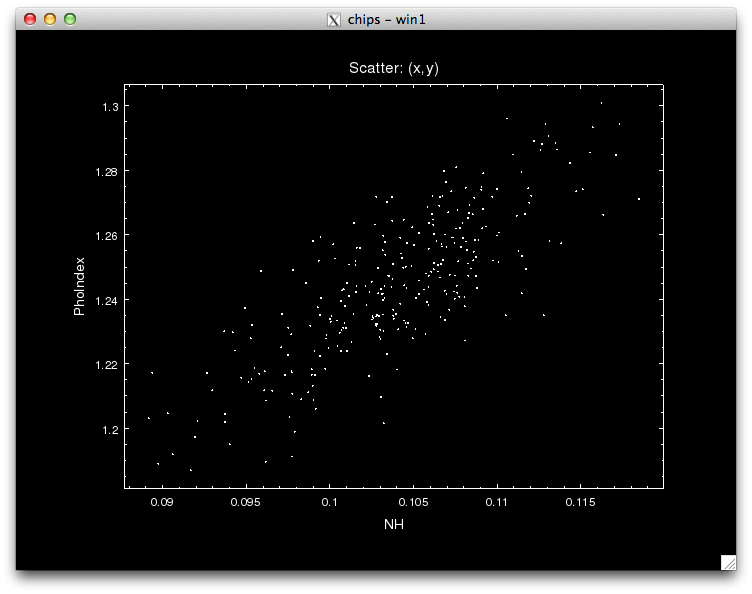
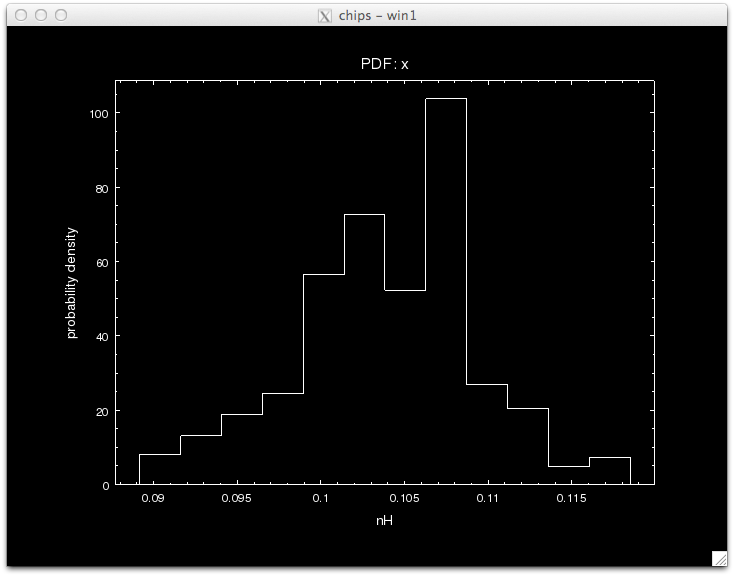
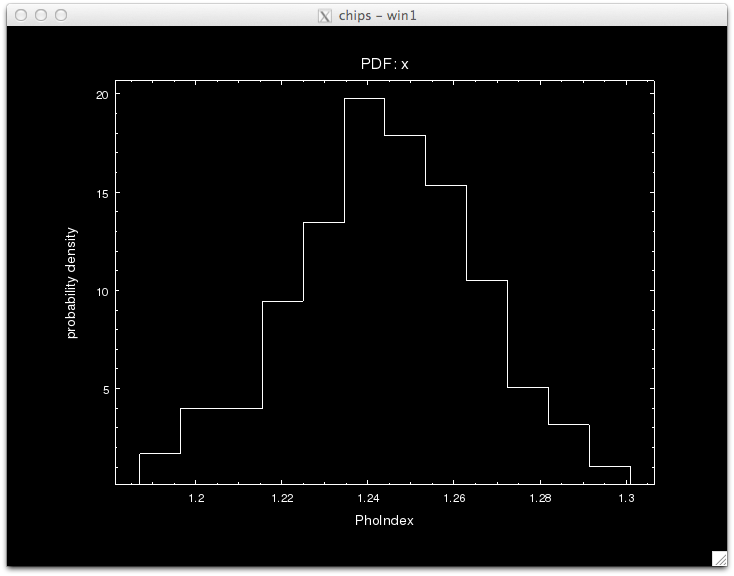
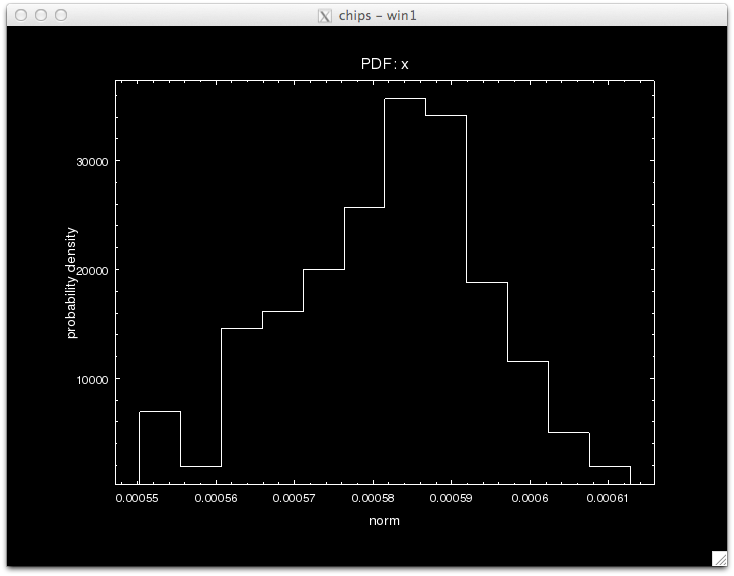
pyBLoCXS takes the current values of its starting point, so different chains with different starting points can be run. Try setting, e.g.,
sherpa> stats_alt, accept_alt, params_alt = get_draws(niter=2000)
Making the Calibration Library: arfmunge
The calibration library is a set of calibration products generated as random samples based on an uncertainty model of the instrument. Jeremy Drake and Pete Ratzlaff have devised a scheme where various subsystem uncertainties are put together to generate a representative sample of possible calibration products (see Drake et al. 2006) This scheme is implemented in a package called MCCal, which generates ARFs and RMFs and fits a specified spectral model to each realization. Please contact them if you wish to try it out. Here, we will consider only Chandra/ACIS-S effective areas, and use the program arfgen (part of MCCal) to generate 500 realizations of the ARF for the Q1127-145 dataset considered above.
arfgen may be run in general as follows, assuming that (a) the perl modules PDL and FITSIOis installed in /home/username/perl5/lib/perl5/, (b) the FITSIO module
These ARFs can be read in to IDL
filarf=file_search('store_arfs/866_*.arf',count=narf) ;filenames of all randomly generated ARFs
arfs=fltarr(n_elements(arf0.SPECRESP),narf) ;array to hold all ARFs
for i=0L,narf-1L do begin & tmp=mrdfits(filarf[i],1,h) & arfs[*,i]=tmp.SPECRESP & endfor ;read in ARFs
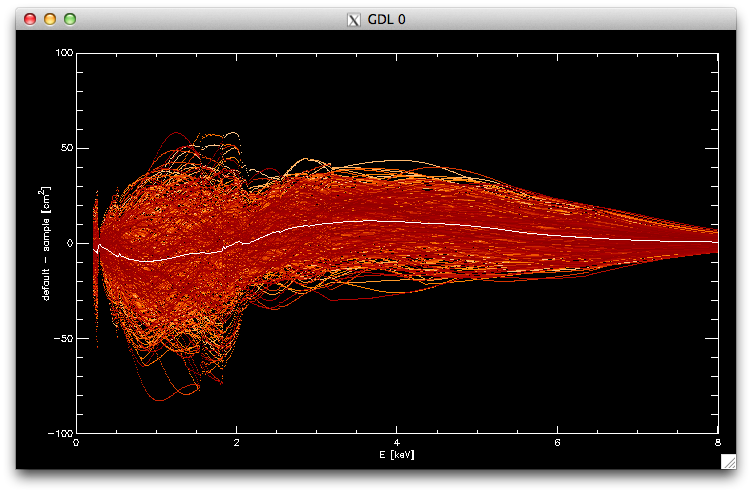
for i=0,narf-1 do oplot,arf0.ENERG_LO,arf0.SPECRESP-arfs[*,i],psym=3,color=((narf-i)/4)+100 ;plot the ARF library
oplot,arf0.ENERG_LO,arf0.SPECRESP-total(arfs,2)/narf ;plot the bias
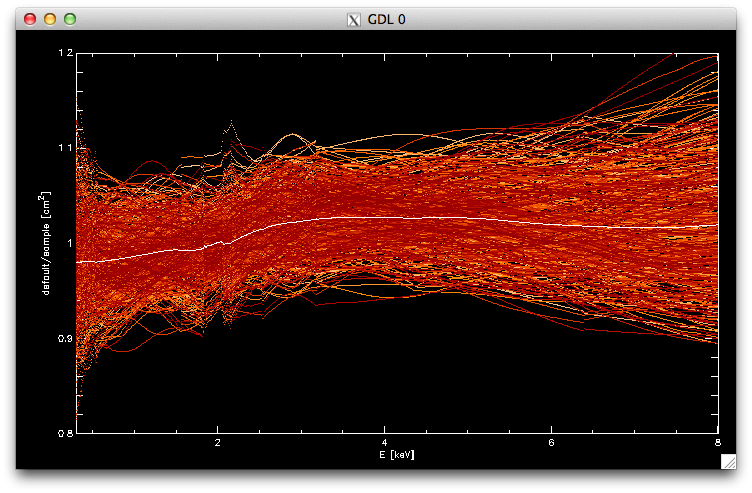
for i=0,narf-1 do oplot,arf0.ENERG_LO,arf0.SPECRESP/arfs[*,i],psym=3,color=((narf-i)/4)+100
oplot,arf0.ENERG_LO,arf0.SPECRESP/(total(arfs,2)/narf)
Compressing the Calibration Library: AREF
The ARF calibration library computed above needs to be ingested into pyBLoCXS in a flexible manner. To do this, we have devised a file format called AREF (Ancillary Response Error Format; Kashyap et al.\ 2008) that is a superset of the OGOP ARF format, and is designed to allow for a large variety of uncertainties to be encoded.
These ARFs can also be consolidated and stored in a single file and used within pyBLoCXS. One of the AREF formats is a method called SIM1DADD. To construct it, use the IDL script samp2fits.pro, which produces the fits file 866_samp_aref.fits.
It is true that disk space is cheap, so there is the option of carrying around full sample libraries for each dataset.
However, because such a strategy can quickly become unwieldy, and Principal Components compression provides other advantages (see Xu et al. 2014).
So here we will show how to make an AREF file that utilizes the PCA1DADD method.
We will first use an R script run_pca_on_arflib.r, which is a wrapper to the R program avgarf_866.txt
pcomps_866.txt
sqlamb_866.txt
sqlambf='sqlamb_866.txt'
pcompf='pcomps_866.txt'
avgarff='avgarf_866.txt'
defarff='obs866/acis.arf'
areffil='866_pca_aref.fits'
vthresh=0.99
verbose=1
pca2aref, sqlambf, pcompf, avgarff, defarff, areffil, vthresh=vthresh, ncomp=ncomp, verbose=verbose
The SAMP AREF file has these extensions --
Block Name Type Dimensions
--------------------------------------------------------------------------------
Block 1: PRIMARY Null
Block 2: SPECRESP Table 6 cols x 1078 rows
Block 3: SIMCOMP Table 2 cols x 500 rows
Block Name Type Dimensions
--------------------------------------------------------------------------------
Block 1: PRIMARY Null
Block 2: SPECRESP Table 6 cols x 1078 rows
Block 3: PCACOMP Table 4 cols x 13 rows
Notice that 99% of the variability in the ARF library is accounted for with just 12 Principal Components (the 13th row in PCACOMP holds the residuals).
Accounting for Calibration Uncertainty
Here, we will demonstrate how to use the AREF files that contain calibration uncertainty information with pyBLoCXS. First, we have to set the sampler,
{'defaultprior': True,
'inv': False,
'log': False,
'nsubiters': 10,
'originalscale': True,
'p_M': 0.5,
'priors': (),
'priorshape': False,
'scale': 1,
'sigma_m': False,
'simarf': None}
Then, we run pyBLoCXS as above:
This takes a substantial amount of time to run, because the code is carrying out fits at every iteration. A faster, optimized version has been developed, but has not been migrated to Sherpa yet. The new versioon also includes set_sampler('fullBayes'), and we plan to make it available in the near future via github.
The standard and prag Bayes analyses may be compared using the posterior density distributions of the model parameters. (Note that the plots are made using a canned analysis; they will be updated using actual AREFs made here later.)
sherpa> plot_pdf(params_pB[0],overplot=True,clearwindow=False)
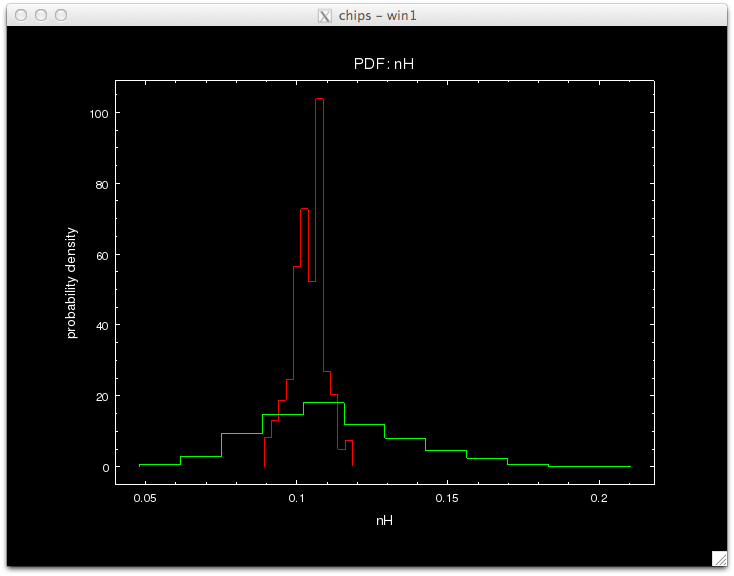
sherpa> plot_pdf(params_pB[1],overplot=True,clearwindow=False)
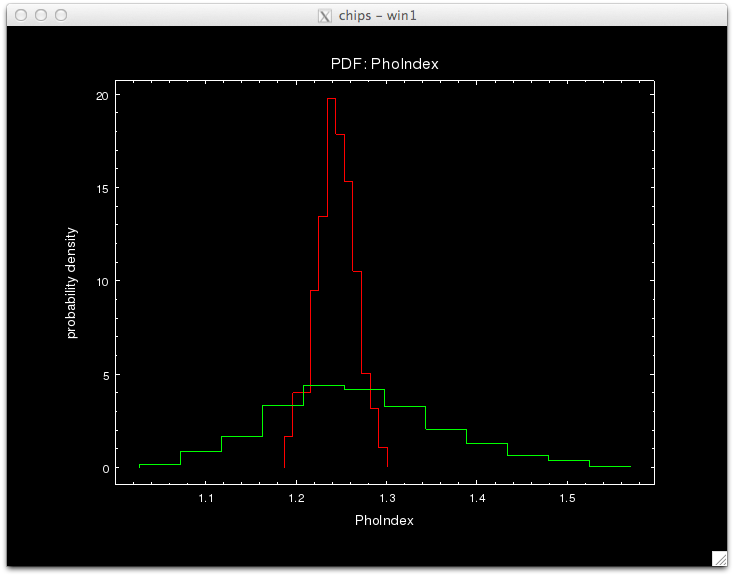
sherpa> plot_pdf(params_pB[2],overplot=True,clearwindow=False)
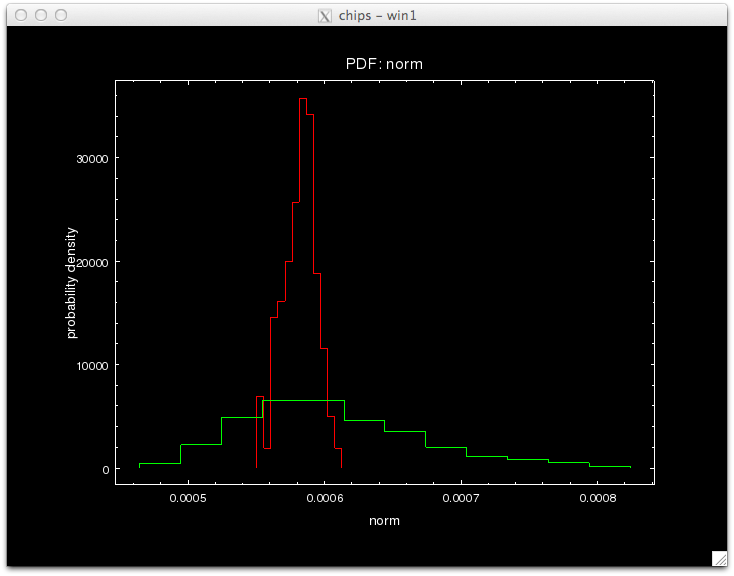
References
- Drake et al. 2006, SPIE 62701I
- 2006SPIE.6270E..49D
- Kashyap et al. 2008, SPIE 7016, 21
- 2008SPIE.7016E..21K
- @CDA [.pdf]
- Lee et al. 2011, ApJ, 731, 126
- 2011ApJ...731..126L
- OGIP ARF standard
- heasarc.gsfc.nasa.gov/docs/heasarc/caldb/docs/memos/cal_gen_92_002/cal_gen_92_002.html
- van Dyk et al. 2001, ApJ, 548, 224
- 2001ApJ...548..224V
- Xu et al. 2014, ApJ, 794, 97
- article [.pdf]
changelog
- 2014-may-27: set up page.
- 2014-jun-15: public version
- 2015-feb-18: updated link to Xu et al.
- 2014-jun-15: public version
