6 Sep 2016
1:07pm EDT
SciCen 706
- Calibration: smart consensus builder
- Abstract:
Useful information to calibrate instruments used for
astrophysical measurements is usually obtained by observing
different sources with well-understood characteristics
simultaneously with different detectors. To do this well,
however, requires a careful modeling of the mean signals, the
intrinsic source variations, and measurement errors. Because
our data are typically large (>>30) photon counts, we
propose an approximate log-normal model, with the advantage of
permitting imperfection in the multiplicative mean modeling to
be captured by the residual variance. The calibration then
takes an analytically tractable form of power shrinkage, with
a half-variance adjustment to ensure an unbiased
multiplicative mean model on the original scale. We
demonstrate the model fitting via data from a combination of
observations of AGNs and spectral line emission from the
supernova remnant E0102, obtained with a variety of X-ray
telescopes like Chandra, XMM-Newton, Suzaku, Swift, etc. The
data are compiled by IACHEC researchers.
4 Oct 2016
1:07pm EDT
SciCen 706
- Some new projects for students
- We will briefly go through a number of possible Astronomy data analysis projects might be of interest to statistics students:
1. Problems that arise when fitting multiple datasets (AZ)
2. Figuring out the range over which a power-law fit works (VK)
3. Model selection using Bayes Factors (AS)
4. Cluster ages from CMDs (AZ)
5. Light curve clarification using HMM (AS)
6. Flare and eclipse onset offsets (VK)
11 Oct 2016
1pm EDT
- Projects
18 Oct 2016
6:07pm BST
Imperial
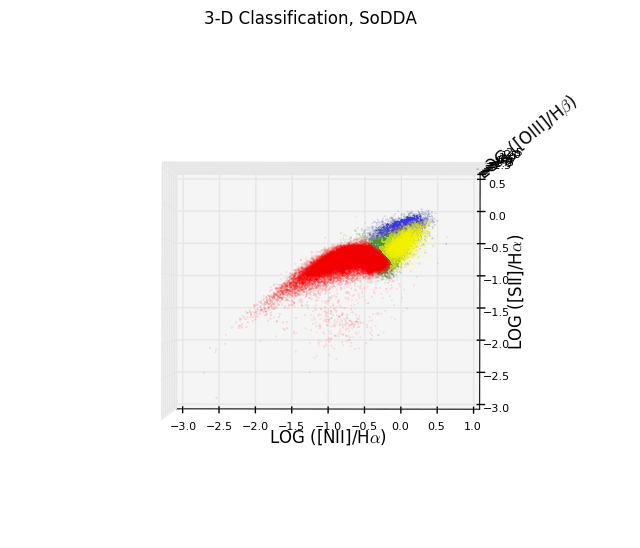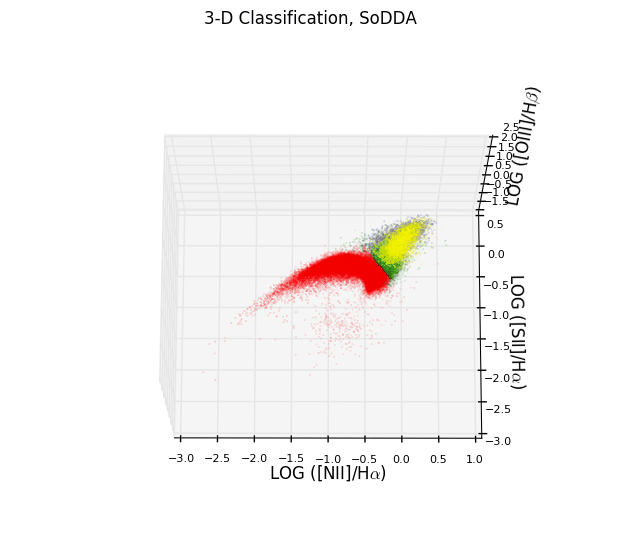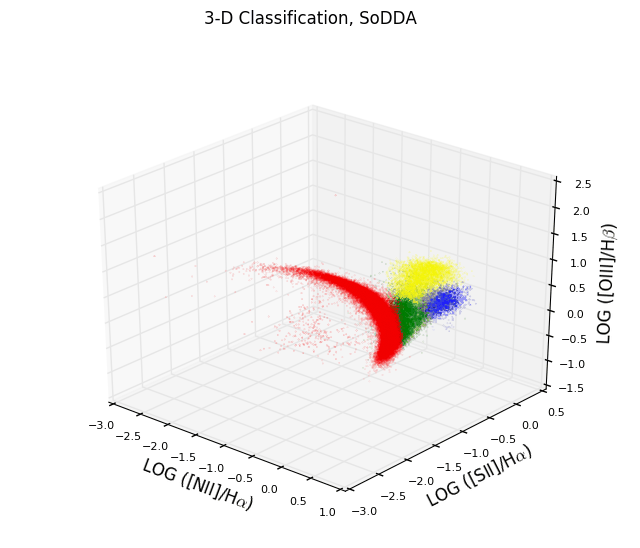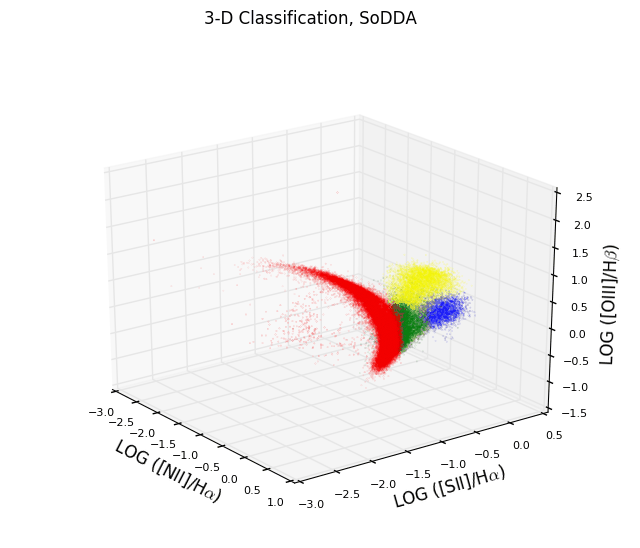
- Multidimensional Data Driven Classification of Active Galaxies
- Abstract:
We propose a new soft clustering scheme for classifying different
galaxy activity classes using 4 emission-line ratios:
log(NII]/Halpha), log([SII]/Halpha), log([OI]/Halpha) and log([OIII]/Halpha).
We fit a big number of multivariate Gaussian distributions to the
Sloan Digital Sky Survey (SDSS) dataset in order to capture local
structures and subsequently group the multivariate Gaussian distributions
to represent the complex multi-dimensional structure of the
joint distribution of the 4 galaxy activity classes. We also introduce
linear multi-dimensional decision surfaces using support vector machines
and we also discuss the sensitivity of our classification scheme when
the OI is not available.
- Presentation slides [.pdf]
 [.gif]
[.gif]
- Presentation slides [.pdf]
25 Oct 2016
SciCen 706
- Probabilistic Cataloguing
- Abstract:
Cataloguing, the act of identifying emission sources
in an observed image and determining their properties,
is a fundamental operation in astronomy. However, when
there are populations of dim sources that are maginally
detectable or when the sources are crowded, a single
catalogue cannot capture the ambiguities of source
identification. Considering cataloguing as a Bayesian
inference problem, we implement a probabilistic cataloguer
that samples the posterior distribution of possible
catalogues. This ensemble of catalogues better recovers
dim and crowded sources. Because the number of sources
is an unknown, the catalogue space is transdimensional,
introducing many challenges, like how to define a prior
on the number of sources.
- Presentation slides: [.pptx] ; [.pdf]
- Presentation slides: [.pptx] ; [.pdf]
15 Nov 2016
Sci Cen 706
- BET on Independence
- Abstract:
We study the problem of model-free dependence detection. This problem
can be difficult even when the marginal distributions are known. We
explain this difficulty by showing the impossibility to uniformly
consistently distinguish degeneracy from independence with any single
test. To make model-free dependence detection a tractable problem, we
introduce the concept of binary expansion statistics (BEStat) and
propose the binary expansion testing (BET) framework. Through simple
mathematics, we convert the dependence detection problem to a multiple
testing problem. Besides being model-free, the BET also enjoys many
other advantages which include (1) invariance to monotone marginal
transformations, (2) clear interpretability of local relationships upon
rejection, and (3) close connections to computing for efficient
algorithms. We illustrate the BET by studying the distribution of the
brightest stars in the night sky.
- Paper: arXiv:1610.05246
- Paper: arXiv:1610.05246
22 Nov 2016
SciCen 706
- The Type Ia Supernova Color�-Magnitude Relation and Host Galaxy Dust: A Simple Hierarchical Bayesian Model
- Abstract:
Type Ia supernovae (SN Ia) are faraway exploding stars used
as ``standardizable candles'' to determine cosmological
distances, measure the accelerating expansion of the
Universe, and constrain the properties of dark energy.
Inferring peak luminosities of SN Ia from
distance-independent observables, such as the shapes and
colors of their light curves (time series), underpins the
evidence for cosmic acceleration. SN Ia with broader,
slower declining optical light curves are more luminous
("broader-brighter") and those with redder colors are
dimmer. But the "redder-dimmer" color-luminosity relation
widely used in cosmological SN Ia analyses confounds its two
separate physical origins. An intrinsic correlation arises
from the physics of exploding white dwarfs, while
interstellar dust in the host galaxy also makes SN Ia appear
redder and dimmer (extinguished). However, conventional SN
Ia cosmology analyses currently use a simplistic linear
regression of magnitude versus color and light curve shape,
which does not model intrinsic SN Ia variations and host
galaxy dust as physically distinct effects, resulting in
unusually low color-magnitude slopes. I have constructed a
probabilistic generative model for the dusty distribution of
extinguished absolute magnitudes and apparent colors as the
convolution of an intrinsic SN Ia color-magnitude
distribution and a host galaxy dust reddening-extinction
distribution. If the intrinsic color-magnitude slope
differs from the host galaxy dust law, this convolution
results in a specific curve of mean extinguished absolute
magnitude vs. apparent color. I incorporated these effects
into a hierarchical Bayesian statistical model for SN Ia
light curve measurements, and analyze an optical light curve
dataset comprising 277 nearby SN Ia at z < 0.10. The
conventional linear fit obtains an effective color-magnitude
slope of 3. My model finds an intrinsic slope of 2.2�0.3
and a distinct dust law of R_B = 3.7�0.3, consistent with
the average properties of Milky Way dust, while correcting a
systematic distance bias of ~0.10 mag in the tails of the
apparent color distribution.
- Paper: arXiv:1609.04470
- Presentation slides [.pdf]
- Paper: arXiv:1609.04470
29 Nov 2016
SciCen 706
- Microlensing by Globular Cluster Stars: using gravitational lensing events to identify mass overdensities
- Abstract:
Optical observers have monitored the Galactic Bulge for twenty five
years, and have discovered roughly 18,000 unique microlensing event
candidates.The number is now sufficient that overdensities, such as
those associated with clusters of stars, can be identified and
studied. We report on the first investigations of such overdensities,
which happen to have been produced by Galactic globular clusters lying
along directions to the Bulge. We expect that similar studies, using
even more data to be collected by new wide-area surveys, will play
important roles in identifying and studying the properties of globular
clusters and dwarf galaxies in our own and other galaxies. In this
talk I will also present an overview of other microlensing-related
opportunities for learning which may be addressed through statistical
studies.
6 Dec 2016
SciCen 706
- Compressed sensing and probabilistic catalogs: Novel approaches to crowded-field stellar photometry
- Abstract:
There are many ways to derive catalogs of astronomical objects
from images, and most of them fail badly in the crowded-field
limit. We are currently exploring two novel approaches.
Compressed sensing allows us to rapidly find candidate stars in
an image. The "probabilistic catalog" technique produces samples
from the posterior probability distribution function on the space
of all possible catalogs, allowing trivial marginalization of
errors introduced by close neighbors. We have applied this
technique to two globular clusters, and found this approach to
yield impressive results. We are currently pondering a hybrid of
these two techniques that retains the speed of the former and
flexibility of the latter, and we welcome input from the
astrostats pundits!
- Presentation slides: BM; DF [.pdf]
- Presentation slides: BM; DF [.pdf]
(Harvard)
24 Jan 2017
SciCen 706
- Multiple overlapping components (Ruobin)
- Ruobin Slides [.pdf]
- Multiple datasets of different sizes (Shihao)
- Shihao Slides [.pdf]
(Harvard)
7 Feb 2017
1:07pm EST
SciCen 706
- Time delay for multiple streams
- Presentation slides [.pdf]
Abstract: As the light from quasars transverses different paths through gravitational field of a galaxy, it generated multiple images on earth with time delay, which provides a way to measure some cosmological parameters, i.e. Hubble constant. The magnitude of images fluctuating over time gives a light curve, as the brightness of source varies as well as microlensing, an low frequency extrinsic variation. Multiple images from the same lensed light source, usually double- or quadruply, produce multiple light curves with time shift. Moreover, lights from multiple filters can be measured for the same system. Estimating time delay remains challenging because of observation seasonal gap, microlensing, etc. In the paper, we introduced a hierarchical Bayesian statespace model to estimate time delay among multiple time series. Our method provides a principled way for estimating time delay, which can take into account different modelings of intrinsic variation of light source and microlensing, which adds another layer of variation independently on these light curves. It can also combine information from multiple filters. We applied our method to Q0957+561 two-filters doubly lensed data and showed benefits from combining data from multiple filters.
14 Feb 2017
1:07pm EST
SciCen 706 / SAMSI
- Separating close sources by their temporal behavior (Luis)
- Luis Slides [.pdf]
- Bounding a good region (Xufei)
- Xufei Slides [.pdf]
28 Feb 2017
1:07pm EST
SAMSI & HU
- A Mixture of Gaussian and Student's t Errors for a Robust and Accurate Inference (Tak)
- Abstract: A Gaussian error assumption, i.e., an assumption that the data are observed up to Gaussian noises, can bias any parameter estimation in the presence of outliers. A heavy tailed error assumption based on Student's t-distribution helps reduce the bias, but it may be less efficient in estimating parameters because the heavy-tail assumption is uniformly applied to most of the normally observed data. We propose a mixture error assumption that selectively converts Gaussian errors into Student's t errors according to latent outlier indicators, leveraging the best of the Gaussian and Student's t errors; a parameter estimation becomes not only robust but also accurate. Using simulated hospital profiling data and astronomical time series of brightness data, we demonstrate the potential for the proposed mixture error assumption to estimate parameters accurately in the presence of outliers.
- Tak slides [.pdf]
- Spacings estimates and good regions (Xufei)
- Xufei slides [.pdf]
7 Mar 2017
1:07pm EST
Raleigh-Durham
- Detecting planets: jointly modeling radial velocity and stellar activity time series
- Abstract:
The radial velocity technique is one of the two main approaches for detecting planets outside our solar system, or exoplanets as they are known in astronomy. The method works by detecting the Doppler shift resulting from the motion of a host star caused by an orbiting planet. Unfortunately, this Doppler signal is typically contaminated by various ``stellar activity" phenomena, such as dark spots on the star surface. A principled approach to recovering the Doppler signal was proposed by Rajpaul et al. (2015), and involves the use of dependent Gaussian processes to jointly model the corrupted Doppler signal and multiple proxies for the stellar activity. Our work in progress aims to extend the Rajpaul et al. (2015) approach by (i) proposing more informative stellar activity proxies, (ii) extending the model to a class of models that can capture our new proxies, and (iii) proposing a model selection procedure to find the best model in the class.
- Presentation slides [.pdf]
- radial velocity movie [.avi]
- spotfull movie [.avi]
- Presentation slides [.pdf]
18 Apr 2017
6:07pm BST
SciCen 706
- Looking for features in astrophysical spectra and images by Testing One Hypothesis Multiple times
- Abstract:
In physics, searches for new particles or new phenomena are
mainly conducted via multiple hypothesis testing. Separate
tests of hypothesis are implemented at different locations
producing an ensemble of local p-values, and the smallest is
reported as evidence for the new emission, once adequately
adjusted to control the false detection rate. An alternative
way to tackle the problem in statistical terms is via Testing
One Hypothesis Multiple times (TOHM). A stochastic process or
a random field indexed by the various alternatives is used to
combine the outcomes of each tests into a single global
p-value, that can be used as as overall standard of evidence.
The resulting statistical tool is particularly well suited for
searches in high energy physics and astrophysics, where the
significance level necessary to claim a discovery is usually
of order of $5\sigma$. Specifically, TOHM targets the
identification of rare signals, and provides valid inference
with respect to stringent significance requirements, without
encountering the problem of over-conservativeness.
25 Apr 2017
1:07pm EST
SciCen 706
- Big Data Inference: Combining Hierarchical Bayes and Machine Learning to Improve Photometric Redshifts for Hyper Suprime Cam
- Abstract: Current and upcoming large-scale surveys will collect multi-band images (photometry) for billions of galaxies. Before these data can be used for many science applications, however, we need to infer distances (redshifts) to them. We outline how rigorous (hierarchical) Bayesian inference -- with some "machine learning" -- can be used to quickly and robustly derive joint "photometric redshift (photo-z)" probability distribution functions (PDFs) to individual galaxies and their parent populations from training data in the "big data" limit. In tandem, we describe the ways we deal with noisy and censored data as well as domain mismatches from a statistical and computational perspective. We validate our methods using mock data and showcase preliminary results on a subset of SDSS data; a restricted implementation using HSC data also appears to perform well. Our next steps will be modeling galaxy redshifting using a continuous, latent process and determining how sensitively our redshift posteriors depend on aspects of our training data. Our code and tests can be found on GitHub.
- Github repository: FRANKEN-Z [url]
- Presentation slides [.pdf]
- Github repository: FRANKEN-Z [url]
16 May 2017
10:07am PDT
Stanford
- Disentangling Time Series Spectra with Gaussian Processes: Applications to Radial Velocity Analysis
- Abstract:
Measurements of radial velocity variations from the
spectroscopic monitoring of stars and their companions are
essential for a broad swath of astrophysics; these
measurements provide access to the fundamental physical
properties that dictate all phases of stellar evolution and
facilitate the quantitative study of planetary systems. The
conversion of those measurements into both constraints on the
orbital architecture and individual component spectra can be a
serious challenge, however, especially for extreme flux ratio
systems and observations with relatively low sensitivity.
Gaussian processes define sampling distributions of flexible,
continuous functions that are well-motivated for modeling
stellar spectra, enabling proficient searches for companion
lines in time-series spectra. We introduce a new technique for
spectral disentangling, where the posterior distributions of
the orbital parameters and intrinsic, rest-frame stellar
spectra are explored simultaneously without needing to invoke
cross-correlation templates. To demonstrate its potential,
this technique is deployed on red-optical time-series spectra
of the mid-M-dwarf eclipsing binary LP661-13, recently
discovered by the MEarth project at Harvard. We report
orbital parameters with improved precision compared to
traditional radial velocity analysis and successfully
reconstruct the primary and secondary spectra. We discuss
potential applications for other stellar and exoplanet radial
velocity techniques and extensions to time-variable spectra.
The code used in this analysis is freely available as an
open-source Python package.
- arXiv:1702.05652 [url]
- arXiv:1702.05652 [url]